
 北京
北京

新智元報道
編輯:定慧 好困
【新智元導讀】Google DeepMind最新AI智能體Aletheia在FirstProof挑戰賽中,獨立攻克了6道世界級數學難題,實現了從競賽水平到PhD科研級的質變。人類數學研究的「手工時代」或許正步入倒計時。
剛剛,人類數學界最后的防線,宣告全面崩塌!
連吃瓜群眾都驚掉下巴:AI不僅會做題,現在居然已經能獨立搞定PhD級別的純粹數學研究了。
就在這兩天,谷歌DeepMind的最新AI研究智能體Aletheia,在數學界一場名為「FirstProof」的巔峰挑戰賽中,一口氣干掉了10道公認的世界級未解數學難題中的6道!
DeepMind的高管Thang Luong在X上難掩激動地發帖:
「對我而言,這甚至比去年歷史性拿下IMO金牌的成就意義還要重大!」
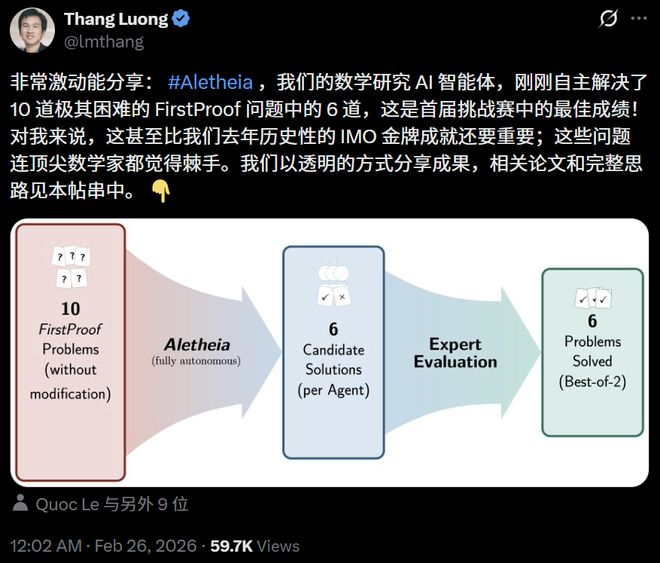
這可不是什么普通的數學競賽。要知道,這些題目連全球最頂尖的數學家都感到極度棘手。

結果,Aletheia不僅自主算出了答案,甚至連提出其中第7題猜想的數學家Jim Fowler本人,都親自出面蓋章確認:
「AI的解題過程,是完全正確的。」

就連當今世界最杰出的天才數學家陶哲軒,都在最新的訪談中表示:AI,已經成為了我的「初級合著者」。

Aletheia的「神之一手」:暴力推演
Aletheia到底有多厲害呢?
來看看谷歌DeepMind首席科學家兼研究主任,超級推理團隊負責人Thang Luong怎么說:
「超級激動!我們的數學科研AI智能體 #Aletheia,剛剛全自主解出了10道出了名變態難的FirstProof挑戰題里的6道,直接拿下了首屆全場最佳!」
大家品品這句話的分量。
Luong直言不諱:
「在我看來,這甚至比咱們去年達到IMO(國際奧數)金牌水平的歷史性時刻,含金量還要高得多!」
因為這些題,是連當今世界上最頂尖的幾位數學大佬都感到極度頭疼的「超級硬骨頭」。
這次,DeepMind跑了兩個基于Gemini 3 DeepThink打造的Aletheia版本(區別僅在于底層模型不同)。
經過多數專家的交叉「會診」,它們聯手干掉了10道題里的6道(分別是第2、5、7、8、9、10題)。

要知道,這套題的判卷評估環節簡直是地獄難度。
因為這世界上能看懂其中這幾道題的專家,都已經是鳳毛麟角。
但也正因如此,DeepMind的研究過程嚴謹到了近乎偏執的地步:
整個解答過程純靠機器自己跑,全程「零人工干預」,而且完完全全是在FirstProof規定的死線內提交的。
這是一個里程碑式的時刻。
不再是人類一步步喂算式,而是AI智能體已經學會了趴在一個極端復雜的科研難題上「死磕」很久,在幾千條死胡同里撞南墻,最后跑回來向人類淡淡匯報一句:「我搞定了(或者搞砸了)。」
DeepMind甚至把Aletheia在這個過程中燒掉的算力(推理成本)做了完整的可視化——

其中最炸裂的,莫過于第7題(P7)的驚天翻盤。
這是一道好幾年都沒人能解開的非典型難題。
據該領域專家Tony Feng透露,在這次比賽里,除了Aletheia,根本沒AI能接近正確答案。

剛開始跑的時候,連DeepMind團隊自己都覺得Aletheia這次肯定沒戲了,結果居然跑出了正確答案!
為了攻克P7,Aletheia投入了海量算力——是當初解開Erd?s-1051問題時的整整16倍!
數學界權威Sang Hyun Kim在看完AI的解題步驟后,給出了極高評價:
「這是我有史以來第一次,看到AI完美無瑕地串聯運用了好幾個極其深奧的數學定理。這絕對是一個獨一無二的稀有案例!」
關于DeepMind對FirstProof的解讀和實驗細節全放這了:

論文地址:https://arxiv.org/abs/2602.21201
不胡說八道,才是AI最硬核的底氣
如果深挖DeepMind這篇論文,你會發現Aletheia之所以這么穩,根本原因在于它掌握了一項關鍵技能:「自我過濾」。
傳統的AI大模型有個臭毛病,就是不懂裝懂(幻覺)。
不管你問啥,它都會一本正經地給你編個答案。
但在科研級別的高端局,如果你給數學家扔一堆看起來極其合理但經不起推敲的廢料,那還不如不給。
DeepMind是怎么解決這個問題的呢?
他們給Aletheia體內設計了兩個「次級人格」:
一個是「生成者(Generator)」,專門負責大開腦洞,瘋狂猜想解題路徑;另一個是冷血無情的「驗證者(Verifier)」,專門負責給「生成者」挑刺。

在解題的黑箱里,這兩個子系統會瘋狂互搏。
當遇到那4道解不出來的問題時,Aletheia沒有選擇強行胡編亂造蒙混過關,而是直接給人類發出:「No solution found(未找到解法)」,或者到了時限直接閉嘴。

不胡編亂造,絕不在沒有把握的地方瞎耗人類專家的精力——這正是Aletheia最讓頂尖學者放心的地方。
正如論文中所寫:「為了提升準確率,我們寧愿犧牲它解答某些問題的能力。」
而在解題成本上,除了P7那道耗費16倍算力的「神題」,其他幾道題解決下來,耗費的「腦力」也都遠遠超出了去年解決Erd?s-1051難題的極值。
想看完整的交互日志和解題過程(對的錯的,原汁原味全公開),直接戳這里:

GitHub地址:
https://github.com/google-deepmind/superhuman/tree/main/aletheia
Aletheia到底手撕了哪些「變態難題」?
先來看看特地提到的P7。

問題背景:代數拓撲/微分幾何。判斷包含二階扭轉元素的半單李群均勻格,能否作為某個萬有覆蓋在有理同調下無圈的緊致無邊界流形的基本群。
答案:不可能。
AI神仙解法:
證明思路一:純拓撲方法(Lefschetz數矛盾)
利用萬有覆蓋Q-無圈的條件,算出2階元素γ的緊支持Lefschetz數必須非零;但γ是自由作用的(沒有不動點),通過歐拉示性數的乘性又推出Lefschetz數必須為零。0 = ±1,矛盾。
證明思路二:幾何方法(對稱空間的剛性)
利用格的幾何結構,構造萬有覆蓋到對稱空間的等變映射,證明γ在兩邊的Lefschetz數必須相等。但在萬有覆蓋一側為零(自由作用),在對稱空間一側非零(Cartan不動點定理保證有不動點)。再次矛盾。
好在哪?
證明一好在「少」。題目給了一堆條件,但全都沒用。只靠最基礎的拓撲工具就解決了問題,而且實際證明了一個更強的結論:任何含扭轉的離散群都不行。鏈條極短:算Lefschetz數,一邊非零一邊為零,矛盾,結束。
證明二好在「深」。它把題目給的幾何條件全部用上了,構造了萬有覆蓋到對稱空間的映射,最終在對稱空間上用Cartan不動點定理找到矛盾。這條路更長,但回答了更本質的問題。。

問題背景:數論/表示論。在非阿基米德局部域上的矩陣群表示中,證明存在一個萬能的Whittaker函數,使得局部Rankin–Selberg積分對所有配對表示都非零。
答案:可以。 存在這樣的「萬能」W。
AI神仙解法:
先選一個特殊的Whittaker函數W,使積分域壓縮到緊集上,復參數s完全消失,問題簡化為證明一個有限泛函非零。然后用反證法:假設對所有V都為零,通過有限Fourier分析推出測試函數具有「平移不變性」,這會迫使表示π在一個比其導子更粗的子群下有不變向量,與導子的定義矛盾。
好在哪?
整個證明最關鍵的就是第一步選取Whittaker函數W。這一個選擇同時做到了三件事:1)把積分域壓縮到緊集上,2)消去了復參數s,3)把無窮維的解析問題變成有限維的代數問題。而且這個W不依賴于配對表示π——同一個選擇對所有π都管用,這在表示論里非常稀有。
反證法部分的「level lowering」也很精彩:假設泛函恒為零,通過有限Fourier分析逐步推出測試函數在模p^{c-1}下不變,但π的導子恰好是p^c,這個層級上不可能有不變向量。矛盾恰好卡在導子的定義上,一步不多一步不少。
對于其他題目,感興趣的讀者可自行查閱論文和GitHub項目。
人類出題的速度,已經快跟不上了
為什么偏偏是數學,成了檢驗AI實力的終極擂臺?
道理很簡單——數學的答案非黑即白,對就是對、錯就是錯,沒有任何讓人類「手下留情」打人情分的空間。
但現在的問題是:出卷的速度,已經被答卷的速度按在地上摩擦了。

2024年11月,Epoch AI上線了FrontierMath評測基準,專門用來摸底最前沿AI的數學推理能力。
剛上線時最強AI連2%的題都做不出來,結果到了今天,GPT-5.2和Claude Opus 4.6已經能搞定基礎題庫40%以上的題目,連50道終極難度的第4級挑戰題,正確率也突破了30%。


不過,FrontierMath再難,本質上還是「人類已有標準答案,看AI能不能也做出來」,說白了還是考試。
但FirstProof里的10道題,是11位頂尖數學家從自己真實科研中掏出來的、從未公開發表過的難題。

項目主頁:https://1stproof.org/
而且這場挑戰賽的結局充滿戲劇性。
2月6日題目放出后,專業學者、民間高手、各大AI實驗室紛紛下場。
到2月14日揭曉答案時,沒有任何人或團隊全部拿下。
隨后,出題者自己拿Gemini 3.0 Deep Think和ChatGPT 5.2 Pro跑了一輪,也只解出了2道。
最終,OpenAI最強內部系統在有限人類監督下解出5道。
對比之下,足以見得這次Aletheia「零人工」干預做出6道題的含金量有多高。
數學圈對此五味雜陳:一部分人直呼逆天,另一部分人覺得10道還剩4道沒解,離替代數學家還遠。
但一個不可逆轉的趨勢已經擺在所有人面前——
我們需要更難的題庫來測AI,而且動作必須快,因為現有的一切正在以肉眼可見的速度過期。
Epoch AI顯然也意識到了這一點。
就在FirstProof開賽同期,他們放出了自己的大招——FrontierMath: Open Problems。





左右滑動查看
這個全新題庫收錄了16道專業數學家死磕過但至今全軍覆沒的真正未解之謎。
更絕的是,雖然沒有標準答案,Epoch AI卻給每道題寫了自動評分程序來判斷AI的解是否成立。
上線至今,沒有任何AI解出哪怕一道——這個「零分」現狀,反而恰恰證明了題庫的價值所在。

FirstProof團隊也沒打算收手,已經官宣3月14日推出難度更變態的第二輪挑戰。

陶哲軒:AI是我的「初級合著者」
那么,站在數學界絕對頂峰的人,到底怎么看這場風暴?
在最新訪談中,陶哲軒給出了一個極其精準的定位:AI現在是他的「初級合著者」。
他2023年曾預測到2026年AI能達到論文合著者水平,當時褒貶不一,現在看進度完全吻合甚至略有超前。

而比這個頭銜更重要的,是陶哲軒描述的一種全新的數學研究范式。
他說,傳統數學研究像是「個案研究」,一篇論文揪著一兩個問題往死里磕,這是數學家幾百年來的工作方式。但AI正在讓數學家第一次有能力做「大樣本普查」。
與此同時,數學研究中有大量極其繁瑣的計算是人類極其討厭做的,所以數學家們會絞盡腦汁想聰明辦法繞過去。但AI不嫌煩,它樂意不知疲倦地把這些枯燥的推演全部跑完。
當AI被整合進人類的工作流,這些曾經讓人望而卻步的障礙就直接被跨過去了。
而在另一個維度上,AI還展現出一種獨特的本事——它能系統性地掃描人類根本沒精力去碰的問題長尾。
以埃爾德什留下的1000多個數學問題為例,AI能把它們從頭到尾過一遍,從中挑出可突破的題目逐個擊破。
人類不可能這么干,但AI可以,而且已經在這么干了。
陶哲軒甚至承認自己從AI的解題過程里學到了東西:
也許它用到了某篇1960年論文里我沒見過的小技巧,它能做到那些人類專家看了一眼就懶得去試的事情。

下一個倒計時已經開始
回看這整場風暴,一條清晰的主線已經浮出水面:
從FrontierMath被快速刷穿,到FirstProof上Aletheia零人工干預拿下6題,再到陶哲軒親口承認AI已是自己的「初級合著者」。
所有信號都在指向同一個事實:
AI正在以一種不可逆的姿態,嵌入人類數學研究的核心流程。
而最值得玩味的,是Epoch AI那個至今「零分」的Open Problems題庫。
它的存在本身就是一個隱喻:
人類現在能拿來考AI的最后武器,是連自己都不知道答案的題目。
這道防線還能守多久?沒人敢打包票。
但有一點幾乎可以確定——
當3月14日FirstProof第二輪挑戰賽開啟的那一刻,今天這篇文章里的所有數字,可能就已經過時了。
參考資料:
https://x.com/rohanpaul_ai/status/2026559039241597070?s=20
https://www.theatlantic.com/technology/2026/02/ai-math-terrance-tao/686107/
特別聲明:以上內容(如有圖片或視頻亦包括在內)為自媒體平臺“網易號”用戶上傳并發布,本平臺僅提供信息存儲服務。
Notice: The content above (including the pictures and videos if any) is uploaded and posted by a user of NetEase Hao, which is a social media platform and only provides information storage services.








































































